
Redis简单学习
Redis(NoSQL)
安装
我们redis是在linux环境下安装的,前置准备需要VM虚拟机、Xshell进行终端操作、Xftp文件传输
压缩包放置 /opt 目录下,并解压
进入解压后的redis目录,依次执行命令
这里没有自定义文件夹,会默认安装到 /usr/local/bin
1
2
3yum install gcc-c++ # 安装C语言的编译环境
make # 源码编译文件
make install # 执行安装我们从解压后的redis目录中,将配置文件提取出来,我就放到 /etc 目录下
编辑配置文件 redis.conf,配置守护进程模式,以便后台运行redis
1
2# 将no改为yes
daemonize yes启动和停止命令
1
2
3
4
5redis-server /etc/redis.conf # 启动,加载配置文件后台运行
redis-cli -p 6379 # 进入命令行操作redis,默认端口6379
# 停止
# 在redis命令行中直接执行shutdown停止redis,然后exit退出命令行
# 或在bin目录下执行redis-cli shutdown
基本信息
默认存在16个数据库,编号0~15,默认选择0号库,在命令行界面使用select 15即可切换到15号库。
Redis是单线程,但通过IO多路复用可支撑高并发,单线程+IO多路复用。
五大数据类型:String、List、Set、Hash、Zset(有序集合)
五大数据类型
Redis 键命令(key)
1 | keys * # 查询所有的键 |
Redis字符串(String)
简述
String类型是二进制安全的,Redis中字符串最大长度是512M。
相关命令(Redis单线程,操作具有原子性)
1
2
3
4
5
6
7
8
9
10
11
12
13set key value # 设置键值对,重复设置会进行值覆盖
get key # 输入键获取值
append key value # 在键对应值后面添加内容,返回添加后的长度
strlen key # 获取键对应值的长度
setnx key value # 设置键值对,但不能覆盖,键已存在则设置失败
incr/decr key # 键的值是integer类型,则数值+1/-1
incrby/decrby key n # 键的值是integer类型,则数值+n/-n
mset/mget # 对多个键执行set、get操作
msetnx # 多个键执行setnx,但只要有一个键重复,就执行失败
getrange key <起始位> <终止位> # 字符串截取起始位数据返回,左闭右闭
setrange key <起始位> value # 字符串对应位置插入值
setex key time value # 设置键值对,但有过期时间
getset key value # 先取旧值,然后赋新值,key没有旧值返回nil数据结构(sds)
String数据结构是简单动态字符串(sds),是可修改的字符串,会自行扩容,但长度不能超过512M。
Redis列表(List)
简述
单键多值,Redis列表按插入顺序排序,是一个双向链表,可以添加元素到头尾,两头操作效率很高,中间节点操作效率低。
相关命令
1
2
3
4
5
6
7
8
9lpush/rpush key value ··· # 从左右插入多个元素
lpop/rpop key # 从左右将数据出列,注意列表为空直接删除
rpoplpush key1 key2 # 列表1右端元素出列然后插入到列表2左端
lrange key <起始位> <终止位> # 左端按索引位置输出列表元素,0 -1则输出全部
lindex key index # 左端按索引取元素
llen key # 对应列表长度
linsert key before/after value newvalue # 列表左端的某个值之前/之后插入新值
lrem key n value # 列表左端删除n个值为value的值,相当于去重
lset key index value # 列表左端索引位的元素替换为新值数据结构(quicklist快速表)
https://blog.csdn.net/qq_53395115/article/details/118961864
快速表quicklist,一般数据量少就是单纯的ZipList压缩列表,当数据较多时,我们使用ZipList+LinkedList组合成quicklist快速链表。
Redis集合(Set)
简述
类似List,但Set无重复。是String类型的无序集合,底层是哈希表。
相关命令
1
2
3
4
5
6
7
8
9
10
11sadd key value ··· # 集合加入多个元素
smembers key # 查询集合所有值
sismember key value # 集合中是否有对应值
scard key # 返回集合元素个数
srem key value ··· # 集合删除元素
spop key # 随机元素出集合,集合为空就删除
smembers key n # 随机从集合取n个值,不删除
smove key1 key2 value # 将集合1的值移动到集合2
sinter key1 key2 # 返回两个集合的交集
sunion key1 key2 # 返回两个集合的并集
sdiff key1 key2 # 返回集合1相对于集合2的差集,也就是1中2没有的部分数据结构(dict字典)
Set数据结构是dict字典,字典是由哈希表实现的。类似于Java的HashSet。
Redis哈希(Hash field-value)
简述
Hash:键值对集合,也就是我们存放的 key-value,这个value是哈希类型,value也是一个键值对 field-value。Hash类型特别适合存储对象。
相关命令
1
2
3
4
5
6
7
8
9
10hset key field value # 给哈希进行键值对赋值,可操作多个键值对
hget key field # 取出哈希field对应的值
hexists key field # 查看是否有哈希键
hkeys key # 取出哈希的所有键
hvals key # 取出哈希的所有值
hincrby key field n # 哈希field对应值进行增量变化,正负数均可
hsetnx key field value # 哈希键值对赋值,若当前哈希field已存在,则不能赋值
hmset key <field value> ··· # 存放多个键值对,也可以使用hset进行多个键值对存储
hmget key field ··· # 取出哈希多个field的值数据结构
- 长度少:ZipList压缩列表
- 长度短:HashTable哈希表
Redis有序集合(Zset)
简述
Zset和Set相当类似,都是没有重复元素的集合。但Zset的每一个元素都关联了一个分数Score,通过这个分数的值来对元素排序,集合的元素是唯一的,但其分数可以是重复的。
相关命令
1
2
3
4
5
6
7
8
9
10
11
12
13zadd key <score value> ··· # 将多个元素及其分数存放到集合中
# 按索引返回集合元素,0 -1返回全部,加上withscores还会返回元素的分数
zrange key <起始位> <终止位> [withscores]
# 集合返回分数在区间之内的元素
zrangebyscore key <min> <max> [withscores]
# 将集合中分数处于范围内的元素从大到小排序
zrevrangebyscore key <max> <min> [withscores]
zincrby key n value # 将集合对应元素的分数加上n
zrem key value # 删除对应的元素
zcount key <min> <max> # 返回集合处于范围的元素个数
zrank key value # 返回元素排名数据结构(Hash/跳跃表)
抽象点就等价于Java的Map <String,Double>
Hash,对于field-value,Zset就相对于value-score的存储结构
跳跃表
https://baike.baidu.com/item/%E8%B7%B3%E8%A1%A8/22819833?fr=aladdin
可以和二分法比较,挺类似的。
三大特殊数据类型
Bitmaps
简述
BItmaps本身不是一种数据类型,实际上是一个字符串,但它可以对字符串进行位操作。
我们可以把Bitmaps看作一个以位为单位的数组,数组每一位只能存储0/1,数组下标在Bitmaps称为偏移量。
相关命令
1
2
3
4
5
6
7
8
9
10# 设置偏移量的值,也就是将数组中某一位改为1
setbit key offset value
# 获取偏移量的值
getbit key offset
# 返回值为1的偏移量的个数,若有范围,则只获取二进制数范围中值为1的偏移量个数
# 二进制数索引从左到右,且end可取负数,-1即末位,-2倒数第二位,依此类推
bitcount key [start end]
# 将多个Bitmaps(key···)进行 and(交集)、or(并集)、not(非)、xor(异或)
# 运算符操作后的结果保存到一个Bitmaps(destkey)
bitop and(or/not/xor) destkey <key···>BItmaps与Set比较
Bitmaps空间效率更高,多用于存储活跃用户,可明显节约空间,但没有活跃用户时,使用Bitmaps反而效率低下,此时使用Set
HyperLogLog
简述
先解释一下基数,比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。说白了就是数集中不重复数的个数。
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
相关命令
1
2
3pfadd key value··· # 加入元素
pfcount key # 返回键的基数
pfmerge destkey <key···> # 多个数集合并
Geospatial(GEO)
简述
Redis提供对GEO类型的支持,即地理信息。该类型就是元素的二维坐标,在地图上的经纬度。
相关命令
1
2
3
4
5
6
7
8
9
10# 添加键的信息,经度、纬度、名称
# 经度范围 -180~180,纬度范围 -85.05112878~85.05112878
geoadd key [longitude latitude member]···
# 根据键、名称取经纬度
geopos key member
# 取两个名称地区间直线距离,可选单位:米、千米、英尺、英里
geodist key member1 member2 m/km/ft/mi
# 以经纬度为圆心,radius为半径的范围中的地区
# 比如经纬度xxx方圆1000英尺的城市
georadius key longitude latitude radius m/km/ft/mi
Redis小知识
Redis发布订阅(pub/sub)
Redis发布订阅是一种消息通信模式,订阅者接收,发布者发送。也就是说当ABC三个Redis客户端都订阅了channel123进入订阅模式,那么Redis客户端X向channel123发送信息,客户端ABC都会接收X发送的信息。相当于我们在视频网站上接收关注的UP的视频信息,以及朋友圈都是类似这种情况。
1 | # 订阅频道1 |
Jedis
依赖
1
2
3
4
5<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>Jedis
我们通过Jedis连接redis,首先要把本机地址的bing注释掉,然后将保护模式设置为no,若还不能连接就关闭linux的防火墙。这里连接是调用Jedis构造器,有多种方法,我们视情况使用,然后Jedis的方法调用和我们redis的命令行一模一样,方法名和命令都是一一对应的。
1
Jedis jedis = new Jedis("192.168.158.129",6379);
Redis与SpringBoot整合
yml配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18spring:
redis:
host: 192.168.158.129
port: 6379
database: 0
# 超时设置,单位ms
connect-timeout: 1800000
# 连接池
lettuce:
pool:
# 连接池最大连接数
max-active: 20
# 最大阻塞等待时间
max-wait: -1
# 连接池最大空闲连接
max-idle: 5
# 最小空闲连接
min-idle: 0依赖
1
2
3
4
5
6
7
8
9<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.2</version>
</dependency>
Redis 事务与锁
multi、exec、discard
- multi:使用命令后,之后的所有命令都会进入一个队列,等待执行。
- exec:把队列的命令执行,是与multi对应使用的。
- discard:队列命令放弃执行,与multi对应使用。
可以说这三个命令就是Redis里面的事务了,一个事务的所有操作都是一致的,
事务中的错误
exec执行前出现错误:
也就是说multi入队时语法发生错误,此时我们执行exec时不允许的,所有命令都失败。
exec执行后出现错误:
multi命令入队没有发生语法错误,但可能有逻辑错误,此时exec可以执行命令,但只有错误命令会失败。
事务中的冲突(锁)
多个操作同时触发,例如3个人的公共钱包,3个人同时在消费。
悲观锁
每次操作前上锁,完成操作后解锁。一个人操作时,不允许其他人操作。
乐观锁(抢票)
给数据加上一个辅助版本,可多人进行操作,但每次操作时比较版本,如果版本改变我们就需要变更数据到最新版本然后再执行操作。
watch、unwatch(监视,乐观锁)
在使用multi命令执行事务前,我们使用watch命令先监视要操作的key,如果在事务执行前key被其他命令改变,那么事务就执行失败。也就是乐观锁。
乐观锁可以解决秒杀的超卖现象。
unwatch也就是取消监视。
Redis事务三特性
单独的隔离操作
事务命令序列化执行,不受其他客户端命令影响。
没有隔离级别
事务在执行前存放于队列中,在执行前任何命令都不会执行。
不保证原子性
事务中有部分命令执行失败,其他命令仍会执行,不会实现回滚。
Redis持久化操作
官方文档:http://www.redis.cn/topics/persistence.html
RDB(默认开启)
简述
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。也就是每隔一段设定好的时间就保存一次。
RDB优点
RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能。
在进行大规模数据恢复时,且数据恢复的完整性不太敏感,使用RDB比AOF更高效。
RDB缺点
最后一次持久化的数据可能会丢失。也就是在保存时间段之间Redis宕机,这段时间的数据只持久化了一部分,剩余的数据就会丢失。
AOF(默认不开启)
简述
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。相当于记录命令,需要恢复时就重新执行。
开启AOF
在redis.conf配置文件中设置appendonly yes就开启了AOF,默认路径和RDB一样。
当AOF和RDB都开启时,Redis会默认使用AOF的数据,通常AOF保存数据集比RDB更完整。
AOF同步频率设置
使用AOF会让你的Redis更加耐久,你可以使用不同的fsync策略:无fsync、每秒fsync、每次写的时候fsync。使用默认的每秒fsync策略,Redis的性能依然很好一旦出现故障,你最多丢失1秒的数据。
在redis.conf中修改,参数与上文对应appendfsync no、appendfsync everysec、appendfsync always。
AOF优点
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写:重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。
AOF 文件有序地保存了对数据库执行的所有写入操作。
AOF缺点
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。
Redis主从复制(读写分离)
配置一主二进行实验
创建myredis文件夹
复制redis.conf配置文件
创建一主二从,共三个配置文件
三个文件分别是redis6379、redis9380、redis6381,文件内容如下,不同文件需要修改端口,然后分别以配置文件运行三个redis-server。
1
2
3
4include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
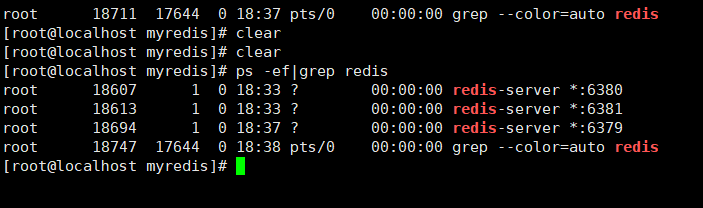
查看三个主机运行情况
1
2
3
4# redis-cli -p 端口号 进入不同主机
redis-cli -p 6379
# 使用该命令查看主从情况
info replication给从机设置主机,实现一主两从
1
2# slaveof ip port
slaveof 127.0.0.1 6379效果
我们在主机中执行些写操作,从机会进行数据同步,我们可用在从机中读取主机中写入的数据。
但在从机中进行写操作会报错,我们从机只允许执行读操作。
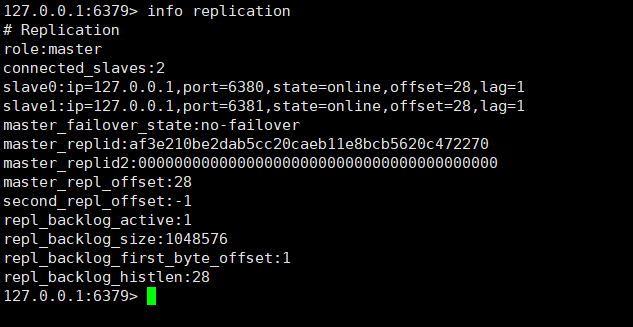
主机/从机宕机
从机挂掉后,其主从关系就消失了。
当我们重新该服务器设置从机时,它会从头复制主机的所有数据。
主机挂掉后,其主从关系不会消失。从机仍会保存主从关系,主机重启后,其主从关系和数据都没有变化。
主从复制原理
- slave连接master,slave向master发送数据同步消息
- master收到slave发送的同步消息,把master数据进行持久化,生成rdb文件,然后将rdb文件发送给slave,slave最后进行rdb文件读取,获取数据。
- 每次master进行写操作后,主动将数据同步到slave
- 前两点就是全量复制,由slave主动发起,最后一点即增量复制,由master发起。
薪火相传(二叉树、分封制)
也就是给主机——从机——从从机,主机下只有一台从机,第二台从机是位于第一台从机下的。和一主二从差不多,但此时从机挂掉,主机和从从机就没有连接了。
反客为主(手动)
当主机挂掉后,使用命令使从机变为主机,该从机后的slave不会修改主从关系。
1 | slaveof no one |
举例:
主机——从机——从从机,主机挂了在从机执行命令:
主机——从从机。
主机——从机,主机——从机。现在是一主二从,在主机挂掉后使用命令:
主机,主机——从机,使用了命令的从机变为主机,但不影响另一个从机的主从关系。
哨兵模式(自动反客为主)
编写哨兵配置文件sentinel.conf
1
2
3# mymaster即给监控服务器起的名字
# 1代表至少要有1个哨兵同意时,才可以数据迁移
sentinel monitor mymaster 127.0.0.1 6379 1启动哨兵
1
redis-sentinel /myredis/sentinel.conf
很明显哨兵端口默认是26379,下面显示了监视的主机6379,和它的两个从机6380、6381,我们主机宕机后,哨兵就会从两个从机中选取一个进行自动反客为主。
反客为主
主机宕机后,哨兵选择一个从机变为主机,其他从机不变,而主机重启后则变为了从机。
哨兵从机选择机制,按序
优先级数值越低越优先
1
2# 优先级,在配置文件668左右
replica-priority 100从机与主机偏移量越大越优先
也就是从机与主机数据同步量越高越优先
runid越小越优先
runid是redis启动后会随机产生一个40位的runid

Redis集群
集群简介
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。集群通过分区来提供一定程度的可用性,即使集群的部分节点失效或无法通讯,集群仍可以继续处理命令请求。
集群可解决Redis扩容问题,可以分摊压力,且一般采用无中心化集群配置。
模拟搭建集群
设置六个节点79、80、81、89、90、91的配置文件,如果已经创建过,需要清空之前的rdb、aof文件。
1
2
3
4
5
6
7
8
9
10include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
# 开启集群
cluster-enabled yes
# 设置节点配置文件名称
cluster-config-file nodes-6379.conf
# 节点超时时效,超时集群则自动进行主从切换
cluster-node-timeout 15000将六个节点合成集群
进入redis最初的安装路径的src目录,我的是在/opt/redis-6.2.5/src。
执行命令
1
2# --cluster-replicas 1 表示集群中每个主机需要一个从机
redis-cli --cluster create --cluster-replicas 1 192.168.158.131:6379 192.168.158.131:6380 192.168.158.131:6381 192.168.158.131:6389 192.168.158.131:6390 192.168.158.131:6391执行命令后会自动分配主从,即79、80、81为主机,89、90、91为从机。
连接操作
1
2
3# 因为集群去中心化,我们任选一个主机当入口都是可行的
# 和一般的连接不同,这里加上-c表示集群
redis-cli -c -p master节点查询
1
cluster nodes
集群是如何分配的?
一个集群至少需要三个主节点
1 | # 该配置指每个主机需要配置1个从机 |
在我们分配时,主主、主从、从从之间都应处于不同IP,也就是所有节点ip都不相同,如果机器挂了,处于相同ip的节点都会挂掉,设置主从就没意义了。
slots(哈希槽)
执行集群合成命令后,会出现这么一个反馈语句
1 | [OK] All 16384 slots covered. |
slots代表哈希槽,这给语句说明一个Redis集群包含16384个哈希槽,数据库中每个键都属于16384个哈希槽的其中一个,插槽是0~16383,共16384个。
集群在创建时,会把哈希槽分割成多个区间,并分配给各个主机。集群在存放key时,会使用CRC16算法来计算key属于哪一个槽的区间,然后就由该主机节点处理相关命令。
我们在集群中添加数据时,会根据计算的哈希槽值来切换主机执行命令,但添加多个值时会出现问题,因为每个值哈希槽值不一样,分配的主机又不一样。
解决多个值添加问题,我们可与将数据合并到一个组内,然后对组进行哈希槽计算并切换对应主机执行。但多建操作仍不方便。
1 | # 这里都是属于num组,看同时添加 |
哈希槽计算
1 | # 获取哈希槽对应值 |
故障恢复
集群中主机挂掉后,其从机马上替代成为主机,主机恢复后变为从机。
在集群中,如果一个主机和其从机都挂掉了,我们会根据集群配置来分情况处理:
1 | cluster-require-full-coverage |
如果该配置是yes,那么整个集群都会挂掉。
如果配置是no,那么只有该主从哈希槽无法使用,其他主机照常运行。
缓存穿透
简介
应用服务器压力突然变大,带来大量访问,一般是先在缓存中查找,再去数据库查找,然后将数据库信息放到缓存中。
而此时大部分数据缓存中都没有,也就是redis命中率低,然后所有访问都会去查询数据库,此时缓存一直查不到数据,redis命中率持续降低,数据库一直承受压力,最后导致数据库崩溃。
简单说是大量请求的 key 不存在于缓存中,导致请求直接来到数据库,缓存失效,最后数据库崩溃,常见是因为非正常url访问导致缓存穿透。
解决办法
- 对空值缓存
- 设置白名单(bitmaps)
- 布隆过滤器(类似bitmaps,有优化)
- 进行实时监控, 设置黑名单
缓存击穿
简介
redis某个key过期,但大量访问要使用了某个key,此时redis已经没有这个key了,所以访问都去查询数据库,导致数据库崩溃。
解决办法
- 预先设置热门数据:在访问高峰来临前,预先存放热门key,并增加热门key的时长。
- 实时调整key的时长,防止过期
- 加锁,逐个操作(降低效率)
缓存雪崩
简介
在极短时间段内,出现大量key集中过期的情况,全部访问都去访问数据库,导致数据库崩溃。
解决办法
构建多级缓存架构(结构复杂)
使用锁或队列(不适用于高并发)
设置过期标志更新缓存:
设置过期提前量,在key快要过期时更新缓存
将缓存失效时间分散:
在key原本失效时间上加上一个随机值,使得缓存中key过期时间重复率降低,难以引发集体失效事件。
分布式锁
简述
简单来说分布式锁就是在集群中,给一台机器上锁,其他所有机器都可以识别,对整个集群的机器都有用。
Redis实现分布式锁
setnx命令就就是分布式锁,我们知道setnx命令是添加不重复的键,其实就是第一次执行后给key上锁,只有释放锁才能继续进行添加操作,也就是删除key才能再次添加。
setnx上锁、del释放锁(手动)。锁一直没有释放,可以给key设置过期时间(自动)。
还可以在上锁时提示设置过期时间:
1 | # nx代表上锁,ex time代表过期时间 |
我们优化一下,上锁时使用uuid
1 | set lock uuid nx ex time |
每一个锁都有对应的uuid,每个锁只能释放对应uuid的锁,以防其他节点误删。
小结
接下来看docker、了解vue,准备搞一个前后端分离项目。八股还没背。。。


